
3 Methods to Solve Your Data Quality Problem Using Python
A guide on how you can solve your data quality problem using Python.


Bad data quality sucks. It causes our reports to be inaccurate and drives our data scientists and engineers to pull their hair out. But most importantly, it causes the trust between the data providers and consumers to deteriorate.
When we finally get around to fixing at least some of the problems, the data team will generally fix it downstream instead of at the source.
So why does that happen? And what can we do about it?
Any graphs created by me will be found here.
How bad data gets into our pipelines
Think about the last time you completed a customer review for an item you bought. How often did you check whether the customer review is grammatically correct, capitalized, or misspelled? Because of these mistakes, saving these customer reviews will result in erroneous data.
Yet, other erroneous data sources enter the database that are not quite as obvious as you might think.
When you sign up for a new videogame or service, think about the birthday you input. If the input value is 01–01–1850 (and that means our age is 172 years old), would it make sense for a 172-year-old to play video games, or better yet, do you think she is even alive?
These values do not make sense within the context and will clutter the database with inaccurate data.
Data Profiling
Data profiling is the first method to identify bad data quality.
Data profiling analyzes data sets; it helps us tackle bad data quality by identifying patterns, outliers, and other key characteristics in a data set and seeing which variables are most predictive for any given outcome. These profiles are also helpful for identifying which variables contain missing values and filling in null values or other gaps.
A data profile can look like this basic example
to what EvidentlyAI, a package that detects these data and concept drifts, can log like this:

And when you click on the sepal width, you will see

The green line represents the mean in the reference dataset, the green band represents the values in the previous dataset, and the red dots represent the current dataset.
Introducing a tool like EvidentlyAI is essential to help identify when your data drifts.

Just like the image portrays, data drifts are exactly like it sounds. These changes naturally occur over time — it can be as drastic as the count of users has increased by over 1000% because a game suddenly became very popular or as small as a subtle bug that only counts distinct values and the average speed went down by 0.5. If this small change is identified early, we can devise a solution and deploy it before the customers know what happened. If you want a deeper dive into data drift, EvidentlyAI wrote an excellent blog here.
Creating data profiles in your data pipelines will be a significant first step as you will learn what your data looks like as it moves through the pipeline.
Data Contracts
The second step would incorporate these data profiles and establish data contracts.
A typical contract is an agreement between two parties, so a data contract is an agreement between the developers and customers of that data. They agree on the values received and sent as part of the data. You can share these acceptable values by writing them on GitHub or whatever the source control system you have set up.
Let’s take this column, for example.

We can see that the minimum date value is 1900–12–31 while the maximum is 1999–12–31. If we wanted to do this programmatically, we could look at the data profile and can set up a flag column using this function:
def check_contract(date: datetime, max_date: datetime, \
min_date: datetime) -> str:
if date > max_date or date < min_date:
return 'out'
else:
return 'in'After filtering the out-of-bounds rows, we can figure out why these values were out of bounds and prevent them from happening. Unfortunately, only considering the boundaries can lead to problems.
If we have only one value of 1900–12–31 and have another value that is 1901–01–02, the value will gladly be accepted. But if this was a birthdate, then it does not make sense. What kind of person would be 120 years old playing video games? The value should be identified and dealt with depending on the context.
This is a perfect example of the limitations of using data contracts, which is why anomaly detection will need to be implemented.
Identifying Anomalies
Anomaly detection is the last and most crucial step in getting clear data quality.
An anomaly can be defined as any event that deviates from normal behavior. In other words, it can be seen as an event that does not conform to what one would expect to find in a normal distribution or pattern.
A normal distribution looks like this.
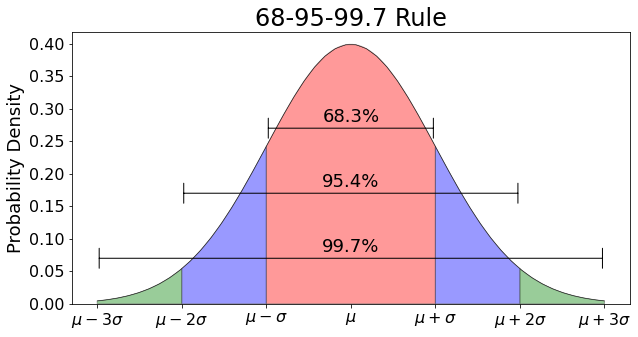
As one can see from the plot, the normal distribution has these properties:
The mean and median are the same.
The standard deviation is the average length from the mean.
68% of the values will be within one standard deviation from the mean
95% of the values will land within two standard deviations from the mean
99.7% of the values would land within three standard deviations from the mean.
The last three are called the “three-sigma rule of thumb.” The values beyond the “three-sigma rule of thumb” would be the anomalies and can be easily calculated if we are looking at one or two features, but what if we compare a lot of columns? We can use machine learning algorithms to find outliers in multivariate problems with great accuracy.
The most common algorithms that are used for anomaly detection are density-based techniques like K-nearest neighbors, Local Outlier Factor, Isolation Forest, etc. Figuring out why these particular sets of machine learning algorithms is so beneficial will be shown when we analyze one of the algorithms more closely.
K-Nearest Neighbors(KNN) is a non-parametric estimation technique used to estimate a data set's density. The ‘k’ value in KNN is how many neighbors it will look at to determine its own “neighborhood.”
Neighborhoods are shaped by the distance between them and the number of points in that neighborhood. The algorithm then finds the center of each neighborhood and draws a line from the nearest point on one side of the neighborhood to the farthest point on the other. This creates a map in which more prominent neighborhoods have more points, and smaller neighborhoods have fewer points. Between the two, there are regions of mixed density. For this algorithm to provide a reasonable estimate, each neighborhood needs many points.
And this is what it looks like in action. I used PyOD’s generate_data function using two features and implemented a SUOD (Scalable Unsupervised Outlier Detection) using three KNN algorithms.
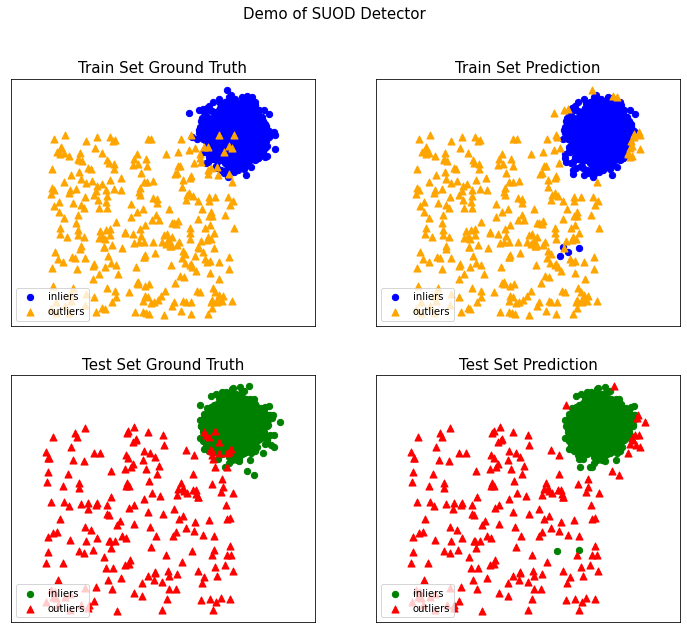
Even though there are apparent wrong predictions, the recall and precision are both high.
On Training Data: SUOD ROC:0.9879, precision @ rank n:0.9333
On Test Data: SUOD ROC:0.992, precision @ rank n:0.925Final words
Anomaly detection concludes the three methods to identify bad data. In combination with data profiling and contracts, you can win this war against bad data quality.