
Installing Clean Code Best Practices for Data Engineering Repositories
From zero to hero. How to set up a Data Engineering project for success.


Beginning a Data Engineering project can be intimidating because of the numerous components involved and the effort required to make progress. It can feel like a daunting task to simply take the first steps.
Today, we will provide recommendations for establishing a successful Data Engineering project repository from the start.
“Getting a clean, concise, and clear scaffolding on which to build your project can give you peace of mind and set the direction of the project.”

Knowing which direction to take can be overwhelming, it’s hard to know when to do what, do something now or later? We will cover the following topics …
● Current open-source tooling option for project/repository setup.
● Common pitfalls and mistakes to avoid when setting up a new DE repository.
● Introduction to baseline DE repository setup.
● Benefits of a clean and simple repository for a new DE project.
The current landscape of repository generation tooling.
First, let’s take a quick look at some of the popular open-source tools available that are used widely for setting up and managing remote repository projects. We will focus on Python repositories, making up the majority of Data Engineering and Data Science use cases.
● poetry
● copier
Not familiar with these project template generators? Most of them work the same. You can run an init command and get some version of the following project directory. Below is an example of a poetry project.

Many of these tools can take out the work to setting up clean repositories. Unfortunately, as a beginner, adding these tools to the repository will require some finesse.
Over time with cookiecutter, when copying and recopying other repositories, it is easy to end up with hundreds of lines of code and tens of files before you’ve written a single line of code.
That being said, when used correctly, these tools can be a great help.
Common pitfalls and mistakes with new repositories.
Whether overusing project template generators or having no standards for project templates, it is easy to fall into these common pitfalls.
● Flat project directory, with no structure.
● No README.md to help give project overview and instructions.
● No testing section (which leads to no tests being written!).
● No containerization (which makes it hard for easy cross-platform use).
● Missing simple files like .gitignore that keep the project clean.
● Too many unused files for tools not used (think YAML files for CI/CD).
These are a few of the common mistakes that are easy to make when generating a new Data Engineering project template. What is the easiest way to avoid these problems?
Introduction to baseline DE repository setup.
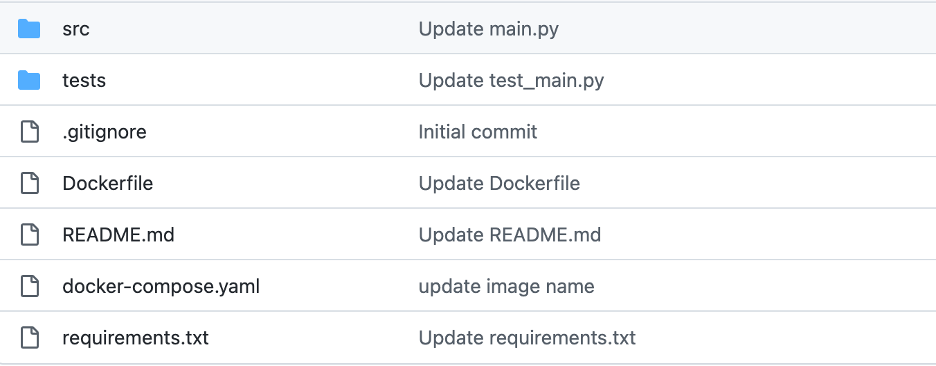
Setting up your first repository doesn’t have to be a daunting task, and can be completed with a few basic requirements that will set you up for success. Many of these fundamentals also enforce good Software Engineering best practices and lay a foundation for moving forward.
See this Data Engineering project template on GitHub for an example.
“The following bullet points are 6 key foundational pieces that should exist in every Data Engineering repository, in some form or other. Of course, there might be slight variations based on the requirements and tools being used in your operation.”
● Each repository should capture project packages in a requirements.txt or similar file.
● Each repository should provide a Docker and optionally docker-compose file that can encapsulate the environment needed to run the project, and increase the ease of development and testing.
● Each repository should contain at least one README.md that gives a project overview and instructions on running tests, etc.
● Each repository should include a “tests” folder that holds the structure required for running unit tests.
● Each repository should hold a .gitignore file that keeps the project clean going forward (blocking IDE and other temp files, credentials, etc).
● Each project should contain a skeleton of an “src” or “main” entry point into the codebase.
If each one of these simple and basic pieces of a new repository is existent, the future development of that repository is set up for success from the beginning. Ignoring any one of these items “for later” can be catastrophic as we all know that most of the time these rarely happen. This can be especially disastrous when we do not provide enough test coverage for our code.
Benefits of a clean and simple repository for a new project.
Although it may seem like a simple task and one that can be taken lightly, setting a good and strong foundation can dictate how a project is viewed and developed in the future.
If you take shortcuts and your initial project repository seems “unclean” and “incomplete” that signals to other team members and users that they might not be able to “trust” that code, or that they can take shortcuts themselves.
From simple steps like including a .gitingore file that blocks cloud credentials from ending up in a remote repository to a testing directory and README that makes clear that unit testing is mandatory, it takes small steps to ensure best practices are in place that will pay dividends on into the future.
 | A guest post by
|