
Introducing English SDK for Spark
Decreasing Your Coding Time in PySpark Workflow with Large Language Models

👋 Hi, this is Sarah with the weekly issue of the Dutch Engineer Newsletter. In this newsletter, I cover data and machine learning concepts, code best practices, and career advice that will help you accelerate your career.
1B+ downloads of Spark per year.1
The popularity of Spark is not surprising given the many tools available for data engineering, data science, and data analytics that have Spark capabilities. I have personally used Spark to pull in terabytes of data through batching and streaming formats without having to change much of my code.
The biggest challenge when learning the Spark framework was the coding language and having to look up the slight differences between Pyspark and Python, or figuring out how to transform a data frame and plot it. Fortunately, this will soon be less of an issue with the English SDK for Spark.
In this tutorial, I will show you how to implement the English SDK for Spark with a California Housing sample dataset. This is just a small glimpse into what the future holds for this tool.
The code can be found here and was run in Google Colaboratory with the provided sample dataset.
Spark Framework
The English SDK for Spark relies on the Spark Framework. This open-source, distributed computing system is used for big data processing. It has been designed in a way that is fast, efficient, and scalable. The framework allows users to process large amounts of data with ease, using languages such as Scala, Pyspark, R, and SQL. By using Spark, we can harness the power of distributed computing to process large amounts of data in parallel, which can significantly reduce the time required for processing. Furthermore, Spark Framework can be used for a variety of applications, including machine learning, data streaming, and graph processing. This makes Spark one of the most versatile and popular big data processing frameworks available today.
Setting Up Environment
LLMs are introduced in the 3.4.1 spark version. I also do not have Hadoop already installed, so I will need to install both the correct spark version and Hadoop. When we check out the archive, only one spark version that meets those requirements is available. http://archive.apache.org/dist/spark/spark-3.4.1/spark-3.4.1-bin-hadoop3.tgz.
#installing the correct pyspark
!apt-get install openjdk-8-jdk-headless -qq > /dev/null
!wget -q <http://archive.apache.org/dist/spark/spark-3.4.1/spark-3.4.1-bin-hadoop3.tgz>
!tar xf spark-3.4.1-bin-hadoop3.tgz
!pip install -q findspark
Setting up these environment variables will let the program know where everything is downloaded and what the api key is for the large language model.
import os
os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64"
os.environ["SPARK_HOME"] = "/content/spark-3.4.1-bin-hadoop3"
os.environ["OPENAI_API_KEY"] = 'your api token'
We will initialize the pyspark server and ensure that we can find the spark session.
import findspark
findspark.init()
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local[*]").getOrCreate()
spark.conf.set("spark.sql.repl.eagerEval.enabled", True) # Property used to format output tables better
spark
returns

We have the correct version of Spark, and the Pyspark shell is recognized, so we are ready to proceed.
Next, we will initialize the langchain for the large language model and pyspark_ai module (also known as the English SDK).
from langchain.chat_models import ChatOpenAI
from pyspark_ai import SparkAI
# If 'gpt-4' is unavailable, use 'gpt-3.5-turbo' (might lower output quality)
llm = ChatOpenAI(model_name='gpt-4', temperature=0)
# Initialize SparkAI with the ChatOpenAI model
spark_ai = SparkAI(llm=llm, verbose=True)
spark_ai.activate()
If you are running into an error that you have exceeded your rate limit, check out this StackOverflow: OpenAI ChatGPT (GPT-3.5) API error 429: "You exceeded your current quota, please check your plan and billing details" [closed]. This error happened to me in both 3.5 and 4.0.
We initialized our libraries and are now ready to read our data.
Read Dataframe
To begin, we will read the CSV file located in the sample_data directory ‘california_housing_test.csv’ that gives a location’s median housing value, median income, population, number of total bedrooms and rooms, and the median age of people living in the houses.
Let’s define the schema.
from pyspark.sql.types import StructType,StructField, StringType, DoubleType
schema = StructType([ \\
StructField('longitude',StringType(),True), \\
StructField('latitude',StringType(),True), \\
StructField('housing_median_age',StringType(),True), \\
StructField('total_rooms', StringType(), True), \\
StructField('total_bedrooms', StringType(), True), \\
StructField('population', DoubleType(), True), \\
StructField('households', StringType(), True),\\
StructField('median_income', StringType(), True),\\
StructField('median_house_value', StringType(), True)
])
Using this schema, we can read in our dataframe. We have added the header option to ensure that the header is read in correctly (and we don’t see any “c0_” in our column names).
df = spark.read.option("header","true").csv('sample_data/california_housing_test.csv',schema=schema)
We have our example csv and can start doing some analysis. Before we do that, we want to make sure median age only have positive values. Here’s how we can do that with the English SDK:
df.ai.verify("expect housing median age to be above 0")This request returns the following response.
INFO: Generated code:
Here is the Python function that checks if the 'housing_median_age' column in the dataframe has all values above 0:
```python
def check_housing_median_age(df) -> bool:
from pyspark.sql.functions import col
# Check if all values in 'housing_median_age' column are above 0
if df.filter(col('housing_median_age') <= 0).count() > 0:
return False
else:
return True
```
Then, you can call this function on your dataframe:
```python
result = check_housing_median_age(df)
```
This function uses PySpark's DataFrame API to filter the rows where 'housing_median_age' is less than or equal to 0. If the count of such rows is more than 0, it means there are some rows with 'housing_median_age' less than or equal to 0, so the function returns False. Otherwise, it returns True.
Great! I will now use this function as part of my process in the future. However, please remember that every time the function runs, it can change the function that it returns. While it is handy to have it available, if you want the process to be repeatable, you should use the function itself. This way, you can create a unit test to verify that it works properly every time.
Creating a User Defined Functions
In Pyspark, a User Defined Function (UDF) is a powerful feature that allows you to define your own functions to manipulate data. With UDFs, you can write complex logic and apply it to your data to transform it in any way you want. Let’s take a look at how we can create them using the English SDK.
@spark_ai.udf
def convert_population(population: float) -> str:
"""Convert the population to a three bucket tiers"""
...
When you run this function, it will return the following result.
def convert_population(population) -> str:
if population is not None:
if population < 1000000:
return 'small'
elif 1000000 <= population < 10000000:
return 'medium'
else:
return 'large'
This function can then be registered in Pyspark.
from pyspark.sql.functions import col, udf
from pyspark.sql.types import StringType
convert_populationUDF = udf(lambda z:convert_population(z),StringType())
I will go ahead and apply the registered function to the population column.
df.withColumn("population tier", convert_populationUDF(col("population"))) \\
.show(truncate=False)
We can now see the extra column “population tier” in the dataframe.
+-----------+---------+------------------+-----------+--------------+----------+-----------+-------------+------------------+---------------+
|longitude |latitude |housing_median_age|total_rooms|total_bedrooms|population|households |median_income|median_house_value|population tier|
+-----------+---------+------------------+-----------+--------------+----------+-----------+-------------+------------------+---------------+
|-122.050000|37.370000|27.000000 |3885.000000|661.000000 |1537.0 |606.000000 |6.608500 |344700.000000 |large |
|-118.300000|34.260000|43.000000 |1510.000000|310.000000 |809.0 |277.000000 |3.599000 |176500.000000 |large |
|-117.810000|33.780000|27.000000 |3589.000000|507.000000 |1484.0 |495.000000 |5.793400 |270500.000000 |large |
|-118.360000|33.820000|28.000000 |67.000000 |15.000000 |49.0 |11.000000 |6.135900 |330000.000000 |small |
|-119.670000|36.330000|19.000000 |1241.000000|244.000000 |850.0 |237.000000 |2.937500 |81700.000000 |large |
|-119.560000|36.510000|37.000000 |1018.000000|213.000000 |663.0 |204.000000 |1.663500 |67000.000000 |large |
|-121.430000|38.630000|43.000000 |1009.000000|225.000000 |604.0 |218.000000 |1.664100 |67000.000000 |large |
|-120.650000|35.480000|19.000000 |2310.000000|471.000000 |1341.0 |441.000000 |3.225000 |166900.000000 |large |
|-122.840000|38.400000|15.000000 |3080.000000|617.000000 |1446.0 |599.000000 |3.669600 |194400.000000 |large |
|-118.020000|34.080000|31.000000 |2402.000000|632.000000 |2830.0 |603.000000 |2.333300 |164200.000000 |large |
|-118.240000|33.980000|45.000000 |972.000000 |249.000000 |1288.0 |261.000000 |2.205400 |125000.000000 |large |
|-119.120000|35.850000|37.000000 |736.000000 |166.000000 |564.0 |138.000000 |2.416700 |58300.000000 |large |
|-121.930000|37.250000|36.000000 |1089.000000|182.000000 |535.0 |170.000000 |4.690000 |252600.000000 |large |
|-117.030000|32.970000|16.000000 |3936.000000|694.000000 |1935.0 |659.000000 |4.562500 |231200.000000 |large |
|-117.970000|33.730000|27.000000 |2097.000000|325.000000 |1217.0 |331.000000 |5.712100 |222500.000000 |large |
|-117.990000|33.810000|42.000000 |161.000000 |40.000000 |157.0 |50.000000 |2.200000 |153100.000000 |medium |
|-120.810000|37.530000|15.000000 |570.000000 |123.000000 |189.0 |107.000000 |1.875000 |181300.000000 |medium |
|-121.200000|38.690000|26.000000 |3077.000000|607.000000 |1603.0 |595.000000 |2.717400 |137500.000000 |large |
|-118.880000|34.210000|26.000000 |1590.000000|196.000000 |654.0 |199.000000 |6.585100 |300000.000000 |large |
|-122.590000|38.010000|35.000000 |8814.000000|1307.000000 |3450.0 |1258.000000|6.172400 |414300.000000 |large |
+-----------+---------+------------------+-----------+--------------+----------+-----------+-------------+------------------+---------------+
That’s all it took to create the UDF.
Transformations
Next, I want to find the top locations with the highest median_house_value. I use the original dataframe and ask the English SDK to transform the data for me.
top_10_house_value = df.ai.transform("find me the top 10 location with the highest median house value")
This request returns
INFO: SQL query for the transform:
SELECT longitude, latitude, median_house_value
FROM temp_view_for_transform
ORDER BY median_house_value DESC
LIMIT 10
That’s exactly what I wanted. Now, I need to write a little note for my documentation to make sure the next person (or my future self) can recollect what I did. I will use explain() function.
top_10_house_value.ai.explain()
This request returns a summary.
In summary, this data frame is retrieving the top 10 records with the highest median house value. It presents the results sorted by median house value in descending order. The output includes the longitude, latitude, and median house value of these records.
Now that I have this code and explanation, I can use it in my documentation in the notebook or on a Confluence page. However, I believe that plotting the median house values will provide greater insight into our data than simply calculating the top 10 values. Let's move on to that next.
Plotting
I am interested in examining the distribution of median house values across different locations. To do this, we will use the values in the dataframe and generate a histogram plot with 20 buckets using the English SDK.
df.ai.plot("histogram of the median house value")
This request returns us with the code and the plot itself.
import pandas as pd
import plotly.express as px
import plotly.io as pio
from pyspark.sql import SparkSession
# Create a SparkSession
spark = SparkSession.builder.getOrCreate()
# Assuming the PySpark DataFrame is already defined as 'df'
# Convert PySpark DataFrame to Pandas DataFrame
pandas_df = df.toPandas()
# Plot the histogram of median house value using Plotly
fig = px.histogram(pandas_df, x='median_house_value', nbins=30)
# Show the plot directly
pio.show(fig)

I am not happy with the current plot because it is difficult to identify which ranges of median_house_values are being filled. Additionally, I do not like the gridlines or the blue background. Let's try creating a new plot with 20 buckets, no gridlines, and a white background.
df.ai.plot("histogram of the median house value into 20 buckets with no grid and background white")
The request returns the following code
import plotly.express as px
import pandas as pd
# Convert Spark DataFrame to Pandas DataFrame
pandas_df = df.toPandas()
# Convert the 'median_house_value' column to numeric
pandas_df['median_house_value'] = pd.to_numeric(pandas_df['median_house_value'])
# Create a histogram
fig = px.histogram(pandas_df, nbins=20, x="median_house_value", color_discrete_sequence=['#1f77b4'])
# Set the background color to white and remove the grid
fig.update_layout(
plot_bgcolor='white',
xaxis=dict(
showgrid=False,
linecolor='black'
),
yaxis=dict(
showgrid=False,
linecolor='black'
)
)
# Display the plot
fig.show()
and the plot.
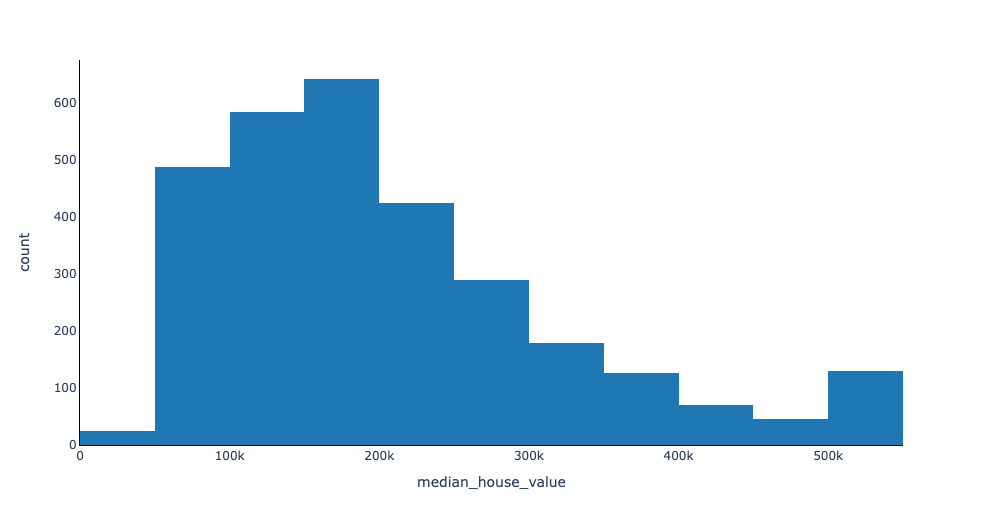
Much better! Now I can see that the majority of median house values fall between 100k and 200k.
I only made a few word changes, and the English SDK helped me achieve the desired result.
Limitations
The English SDK for Spark offers many possibilities for data professionals. However, there is a major limitation that needs to be addressed since it will prevent most of us from using it in production. Currently, the English SDK only supports GPT-4 or GPT-3.5-turbo from OpenAI. This means that you need to have an OpenAI account with billing enabled. Keep in mind that whatever data you use with this tool can be used and stored in OpenAI, so be careful what you use. Without the ability to use privately trained models, this may not be a viable option for many of us.
Final Thoughts
Today's article covered three aspects of English SDK for Spark: creating a user-defined function, transformations, and plots. This SDK is a powerful tool for data engineers, data scientists, and data analysts as we no longer have to google and context switch to identify what we need. However, the inability to add privately trained models may limit its usefulness for production implementation.